Vector stores
This conceptual overview focuses on text-based indexing and retrieval for simplicity. However, embedding models can be multi-modal and vector stores can be used to store and retrieve a variety of data types beyond text.
Overview
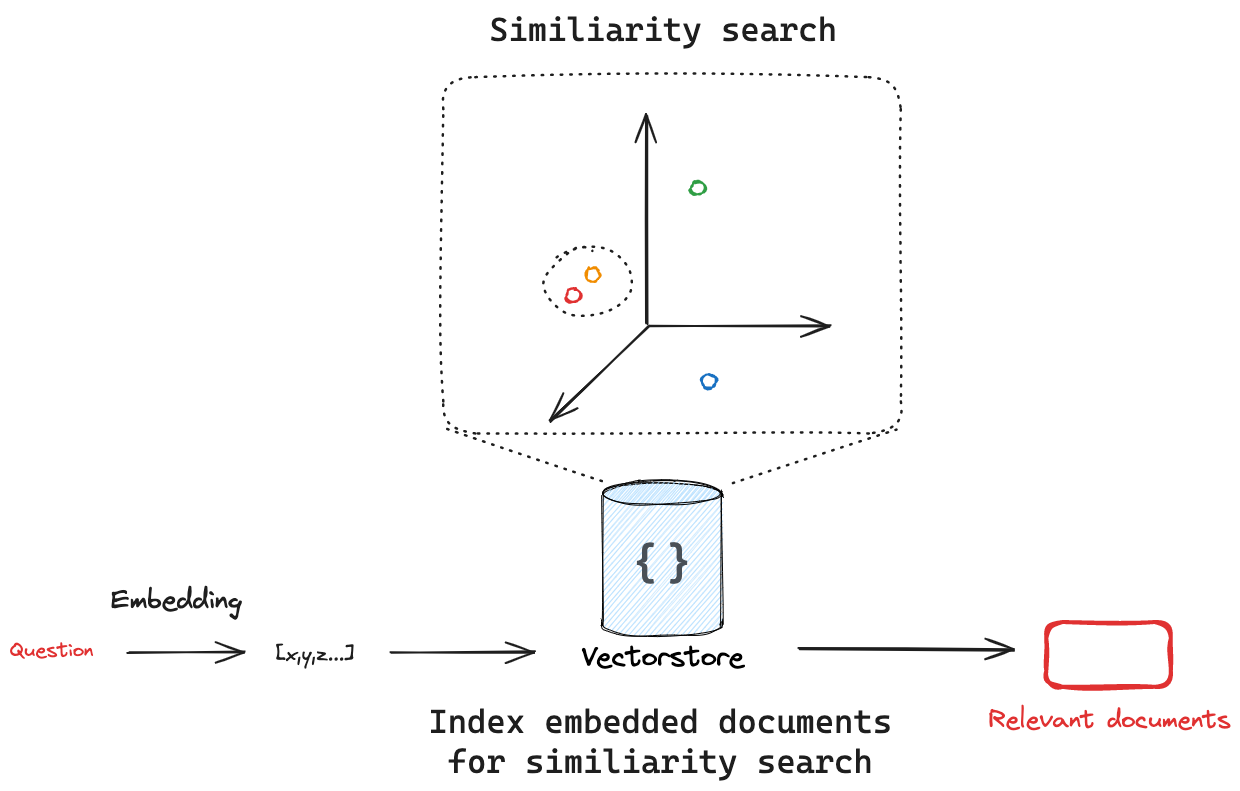
Vector stores are specialized data stores that enable indexing and retrieving information based on vector representations.
These vectors, called embeddings, capture the semantic meaning of data that has been embedded.
Vector stores are frequently used to search over unstructured data, such as text, images, and audio, to retrieve relevant information based on semantic similarity rather than exact keyword matches.
Integrations
LangChain has a large number of vectorstore integrations, allowing users to easily switch between different vectorstore implementations.
Please see the full list of LangChain vectorstore integrations.
Interface
LangChain provides a standard interface for working with vector stores, allowing users to easily switch between different vectorstore implementations.
The interface consists of basic methods for writing, deleting and searching for documents in the vector store.
The key methods are:
add_documents: Add a list of texts to the vector store.delete_documents: Delete a list of documents from the vector store.similarity_search: Search for similar documents to a given query.
Initialization
Most vectors in LangChain accept an embedding model as an argument when initializing the vector store.
We will use LangChain's InMemoryVectorStore implementation to illustrate the API.
from langchain_core.vectorstores import InMemoryVectorStore
# Initialize with an embedding model
vector_store = InMemoryVectorStore(embedding=SomeEmbeddingModel())
Adding documents
To add documents, use the add_documents method.
This API works with a list of Document objects.
Document objects all have page_content and metadata attributes, making them a universal way to store unstructured text and associated metadata.
from langchain_core.documents import Document
document_1 = Document(
page_content="I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
You should usually provide IDs for the documents you add to the vector store, so that instead of adding the same document multiple times, you can update the existing document.
vector_store.add_documents(documents=documents, ids=["doc1", "doc2"])
Delete
To delete documents, use the delete_documents method which takes a list of document IDs to delete.
vector_store.delete_documents(ids=["doc1"])
Search
Vector stores embed and store the documents that added. If we pass in a query, the vectorstore will embed the query, perform a similarity search over the embedded documents, and return the most similar ones. This captures two important concepts: first, there needs to be a way to measure the similarity between the query and any embedded document. Second, there needs to be an algorithm to efficiently perform this similarity search across all embedded documents.
Similarity metrics
A critical advantage of embeddings vectors is they can be compared using many simple mathematical operations:
- Cosine Similarity: Measures the cosine of the angle between two vectors.
- Euclidean Distance: Measures the straight-line distance between two points.
- Dot Product: Measures the projection of one vector onto another.
The choice of similarity metric can sometimes be selected when initializing the vectorstore. Please refer to the documentation of the specific vectorstore you are using to see what similarity metrics are supported.
- See this documentation from Google on similarity metrics to consider with embeddings.
- See Pinecone's blog post on similarity metrics.
- See OpenAI's FAQ on what similarity metric to use with OpenAI embeddings.
Similarity search
Given a similarity metric to measure the distance between the embedded query and any embedded document, we need an algorithm to efficiently search over all the embedded documents to find the most similar ones.
There are various ways to do this. As an example, many vectorstores implement HNSW (Hierarchical Navigable Small World), a graph-based index structure that allows for efficient similarity search.
Regardless of the search algorithm used under the hood, the LangChain vectorstore interface has a similarity_search method for all integrations.
This will take the search query, create an embedding, find similar documents, and return them as a list of Documents.
query = "my query"
docs = vectorstore.similarity_search(query)
Many vectorstores support search parameters to be passed with the similarity_search method. See the documentation for the specific vectorstore you are using to see what parameters are supported.
As an example Pinecone several parameters that are important general concepts:
Many vectorstores support the k, which controls the number of Documents to return, and filter, which allows for filtering documents by metadata.
query (str) – Text to look up documents similar to.k (int) – Number of Documents to return. Defaults to 4.filter (dict | None) – Dictionary of argument(s) to filter on metadata
- See the how-to guide for more details on how to use the
similarity_searchmethod. - See the integrations page for more details on arguments that can be passed in to the
similarity_searchmethod for specific vectorstores.
Metadata filtering
While vectorstore implement a search algorithm to efficiently search over all the embedded documents to find the most similar ones, many also support filtering on metadata. This allows structured filters to reduce the size of the similarity search space. These two concepts work well together:
- Semantic search: Query the unstructured data directly, often using via embedding or keyword similarity.
- Metadata search: Apply structured query to the metadata, filering specific documents.
Vector store support for metadata filtering is typically dependent on the underlying vector store implementation.
Here is example usage with Pinecone, showing that we filter for all documents that have the metadata key source with value tweet.
vectorstore.similarity_search(
"LangChain provides abstractions to make working with LLMs easy",
k=2,
filter={"source": "tweet"},
)
- See Pinecone's documentation on filtering with metadata.
- See the list of LangChain vectorstore integrations that support metadata filtering.
Advanced search and retrieval techniques
While algorithms like HNSW provide the foundation for efficient similarity search in many cases, additional techniques can be employed to improve search quality and diversity.
For example, maximal marginal relevance is a re-ranking algorithm used to diversify search results, which is applied after the initial similarity search to ensure a more diverse set of results.
As a second example, some vector stores offer built-in hybrid-search to combine keyword and semantic similarity search, which marries the benefits of both approaches.
At the moment, there is no unified way to perform hybrid search using LangChain vectorstores, but it is generally exposed as a keyword argument that is passed in with similarity_search.
See this how-to guide on hybrid search for more details.
| Name | When to use | Description |
|---|---|---|
| Hybrid search | When combining keyword-based and semantic similarity. | Hybrid search combines keyword and semantic similarity, marrying the benefits of both approaches. Paper. |
| Maximal Marginal Relevance (MMR) | When needing to diversify search results. | MMR attempts to diversify the results of a search to avoid returning similar and redundant documents. |