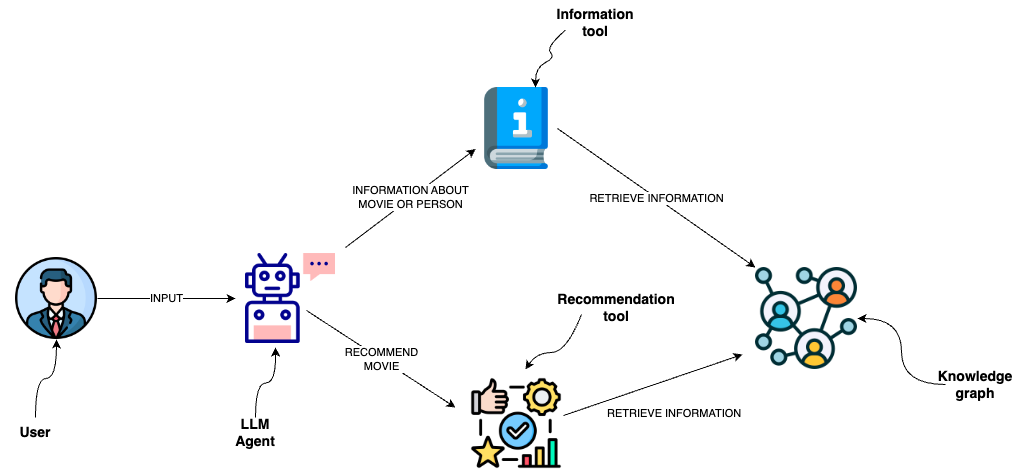
How to add a semantic layer over graph database
You can use database queries to retrieve information from a graph database like Neo4j. One option is to use LLMs to generate Cypher statements. While that option provides excellent flexibility, the solution could be brittle and not consistently generating precise Cypher statements. Instead of generating Cypher statements, we can implement Cypher templates as tools in a semantic layer that an LLM agent can interact with.
Setup
First, get required packages and set environment variables:
%pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
Note: you may need to restart the kernel to use updated packages.
We default to OpenAI models in this guide, but you can swap them out for the model provider of your choice.
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
········
Next, we need to define Neo4j credentials. Follow these installation steps to set up a Neo4j database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
The below example will create a connection with a Neo4j database and will populate it with example data about movies and their actors.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
[]
Custom tools with Cypher templates
A semantic layer consists of various tools exposed to an LLM that it can use to interact with a knowledge graph. They can be of various complexity. You can think of each tool in a semantic layer as a function.
The function we will implement is to retrieve information about movies or their cast.
from typing import Optional, Type
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
# Import things that are needed generically
from pydantic import BaseModel, Field
description_query = """
MATCH (m:Movie|Person)
WHERE m.title CONTAINS $candidate OR m.name CONTAINS $candidate
MATCH (m)-[r:ACTED_IN|HAS_GENRE]-(t)
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
WITH m, collect(types) as contexts
WITH m, "type:" + labels(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
+ "\nyear: "+coalesce(m.released,"") +"\n" +
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as context
RETURN context LIMIT 1
"""
def get_information(entity: str) -> str:
try:
data = graph.query(description_query, params={"candidate": entity})
return data[0]["context"]
except IndexError:
return "No information was found"
You can observe that we have defined the Cypher statement used to retrieve information. Therefore, we can avoid generating Cypher statements and use the LLM agent to only populate the input parameters. To provide additional information to an LLM agent about when to use the tool and their input parameters, we wrap the function as a tool.
from typing import Optional, Type
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
# Import things that are needed generically
from pydantic import BaseModel, Field
class InformationInput(BaseModel):
entity: str = Field(description="movie or a person mentioned in the question")
class InformationTool(BaseTool):
name = "Information"
description = (
"useful for when you need to answer questions about various actors or movies"
)
args_schema: Type[BaseModel] = InformationInput
def _run(
self,
entity: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return get_information(entity)
async def _arun(
self,
entity: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
return get_information(entity)
OpenAI Agent
LangChain expression language makes it very convenient to define an agent to interact with a graph database over the semantic layer.
from typing import List, Tuple
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = [InformationTool()]
llm_with_tools = llm.bind(functions=[convert_to_openai_function(t) for t in tools])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that finds information about movies "
" and recommends them. If tools require follow up questions, "
"make sure to ask the user for clarification. Make sure to include any "
"available options that need to be clarified in the follow up questions "
"Do only the things the user specifically requested. ",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
def _format_chat_history(chat_history: List[Tuple[str, str]]):
buffer = []
for human, ai in chat_history:
buffer.append(HumanMessage(content=human))
buffer.append(AIMessage(content=ai))
return buffer
agent = (
{
"input": lambda x: x["input"],
"chat_history": lambda x: _format_chat_history(x["chat_history"])
if x.get("chat_history")
else [],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "Who played in Casino?"})
[1m> Entering new AgentExecutor chain...[0m
[32;1m[1;3m
Invoking: `Information` with `{'entity': 'Casino'}`
[0m[36;1m[1;3mtype:Movie
title: Casino
year: 1995-11-22
ACTED_IN: Joe Pesci, Robert De Niro, Sharon Stone, James Woods
[0m[32;1m[1;3mThe movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.[0m
[1m> Finished chain.[0m
{'input': 'Who played in Casino?',
'output': 'The movie "Casino" starred Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}