Conversational RAG
This guide assumes familiarity with the following concepts:
In many Q&A applications we want to allow the user to have a back-and-forth conversation, meaning the application needs some sort of "memory" of past questions and answers, and some logic for incorporating those into its current thinking.
In this guide we focus on adding logic for incorporating historical messages. Further details on chat history management is covered here.
We will cover two approaches:
- Chains, in which we always execute a retrieval step;
- Agents, in which we give an LLM discretion over whether and how to execute a retrieval step (or multiple steps).
For the external knowledge source, we will use the same LLM Powered Autonomous Agents blog post by Lilian Weng from the RAG tutorial.
Setup
Dependencies
We'll use OpenAI embeddings and a simple in-memory vector store in this walkthrough, but everything shown here works with any Embeddings, and VectorStore or Retriever.
We'll use the following packages:
%%capture --no-stderr
%pip install --upgrade --quiet langchain langchain-community beautifulsoup4
We need to set environment variable OPENAI_API_KEY, which can be done directly or loaded from a .env file like so:
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass()
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
Note that LangSmith is not needed, but it is helpful. If you do want to use LangSmith, after you sign up at the link above, make sure to set your environment variables to start logging traces:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
if not os.environ.get("LANGCHAIN_API_KEY"):
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Chains
Let's first revisit the Q&A app we built over the LLM Powered Autonomous Agents blog post by Lilian Weng in the RAG tutorial.
- OpenAI
- Anthropic
- Azure
- Cohere
- NVIDIA
- FireworksAI
- Groq
- MistralAI
- TogetherAI
- AWS
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
pip install -qU langchain-anthropic
import getpass
import os
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-5-sonnet-20240620")
pip install -qU langchain-openai
import getpass
import os
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
import getpass
import os
os.environ["GOOGLE_API_KEY"] = getpass.getpass()
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model="gemini-1.5-flash")
pip install -qU langchain-cohere
import getpass
import os
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import ChatCohere
llm = ChatCohere(model="command-r-plus")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
import os
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain import ChatNVIDIA
llm = ChatNVIDIA(model="meta/llama3-70b-instruct")
pip install -qU langchain-fireworks
import getpass
import os
os.environ["FIREWORKS_API_KEY"] = getpass.getpass()
from langchain_fireworks import ChatFireworks
llm = ChatFireworks(model="accounts/fireworks/models/llama-v3p1-70b-instruct")
pip install -qU langchain-groq
import getpass
import os
os.environ["GROQ_API_KEY"] = getpass.getpass()
from langchain_groq import ChatGroq
llm = ChatGroq(model="llama3-8b-8192")
pip install -qU langchain-mistralai
import getpass
import os
os.environ["MISTRAL_API_KEY"] = getpass.getpass()
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest")
pip install -qU langchain-openai
import getpass
import os
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.together.xyz/v1",
api_key=os.environ["TOGETHER_API_KEY"],
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
)
pip install -qU langchain-aws
# Ensure your AWS credentials are configured
from langchain_aws import ChatBedrock
llm = ChatBedrock(model_id="anthropic.claude-3-5-sonnet-20240620-v1:0")
import bs4
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1. Load, chunk and index the contents of the blog to create a retriever.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = InMemoryVectorStore.from_documents(
documents=splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
# 2. Incorporate the retriever into a question-answering chain.
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
response = rag_chain.invoke({"input": "What is Task Decomposition?"})
response["answer"]
"Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and provides insight into the model's reasoning."
Note that we have used the built-in chain constructors create_stuff_documents_chain and create_retrieval_chain, so that the basic ingredients to our solution are:
- retriever;
- prompt;
- LLM.
This will simplify the process of incorporating chat history.
Adding chat history
The chain we have built uses the input query directly to retrieve relevant context. But in a conversational setting, the user query might require conversational context to be understood. For example, consider this exchange:
Human: "What is Task Decomposition?"
AI: "Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable for an agent or model."
Human: "What are common ways of doing it?"
In order to answer the second question, our system needs to understand that "it" refers to "Task Decomposition."
We'll need to update two things about our existing app:
- Prompt: Update our prompt to support historical messages as an input.
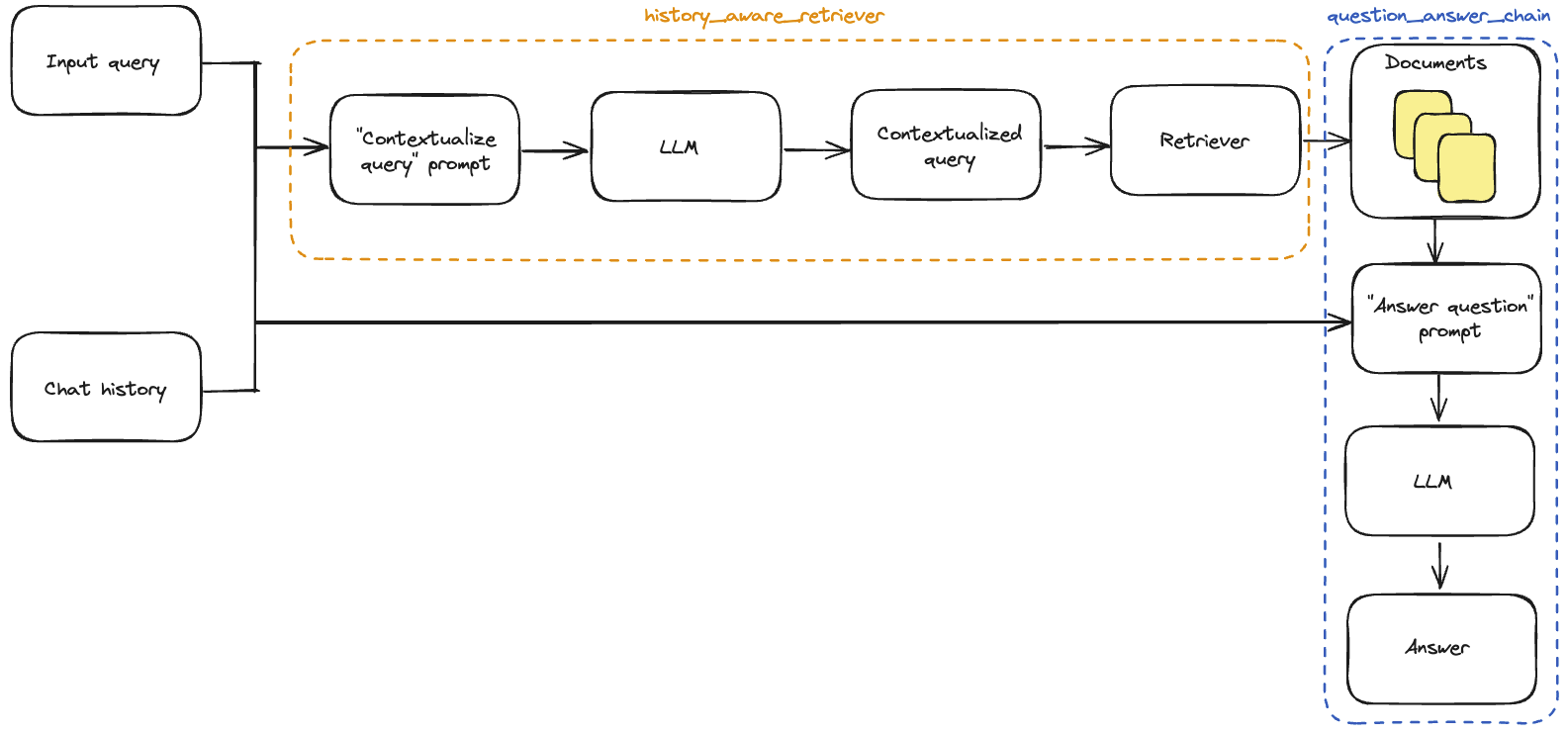
- Contextualizing questions: Add a sub-chain that takes the latest user question and reformulates it in the context of the chat history. This can be thought of simply as building a new "history aware" retriever. Whereas before we had:
query->retriever
Now we will have:(query, conversation history)->LLM->rephrased query->retriever
Contextualizing the question
First we'll need to define a sub-chain that takes historical messages and the latest user question, and reformulates the question if it makes reference to any information in the historical information.
We'll use a prompt that includes a MessagesPlaceholder variable under the name "chat_history". This allows us to pass in a list of Messages to the prompt using the "chat_history" input key, and these messages will be inserted after the system message and before the human message containing the latest question.
Note that we leverage a helper function create_history_aware_retriever for this step, which manages the case where chat_history is empty, and otherwise applies prompt | llm | StrOutputParser() | retriever in sequence.
create_history_aware_retriever constructs a chain that accepts keys input and chat_history as input, and has the same output schema as a retriever.
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
This chain prepends a rephrasing of the input query to our retriever, so that the retrieval incorporates the context of the conversation.
Now we can build our full QA chain. This is as simple as updating the retriever to be our new history_aware_retriever.
Again, we will use create_stuff_documents_chain to generate a question_answer_chain, with input keys context, chat_history, and input-- it accepts the retrieved context alongside the conversation history and query to generate an answer. A more detailed explaination is over here
We build our final rag_chain with create_retrieval_chain. This chain applies the history_aware_retriever and question_answer_chain in sequence, retaining intermediate outputs such as the retrieved context for convenience. It has input keys input and chat_history, and includes input, chat_history, context, and answer in its output.
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
Let's try this. Below we ask a question and a follow-up question that requires contextualization to return a sensible response. Because our chain includes a "chat_history" input, the caller needs to manage the chat history. We can achieve this by appending input and output messages to a list:
from langchain_core.messages import AIMessage, HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend(
[
HumanMessage(content=question),
AIMessage(content=ai_msg_1["answer"]),
]
)
second_question = "What are common ways of doing it?"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])
Common ways of task decomposition include using simple prompting techniques, such as asking for "Steps for XYZ" or "What are the subgoals for achieving XYZ?" Additionally, task-specific instructions can be employed, like "Write a story outline" for writing tasks, or human inputs can guide the decomposition process.
Check out the LangSmith trace.
Stateful management of chat history
This section of the tutorial previously used the RunnableWithMessageHistory abstraction. You can access that version of the documentation in the v0.2 docs.
As of the v0.3 release of LangChain, we recommend that LangChain users take advantage of LangGraph persistence to incorporate memory into new LangChain applications.
If your code is already relying on RunnableWithMessageHistory or BaseChatMessageHistory, you do not need to make any changes. We do not plan on deprecating this functionality in the near future as it works for simple chat applications and any code that uses RunnableWithMessageHistory will continue to work as expected.
Please see How to migrate to LangGraph Memory for more details.
We have added application logic for incorporating chat history, but we are still manually plumbing it through our application. In production, the Q&A application will usually persist the chat history into a database, and be able to read and update it appropriately.
LangGraph implements a built-in persistence layer, making it ideal for chat applications that support multiple conversational turns.
Wrapping our chat model in a minimal LangGraph application allows us to automatically persist the message history, simplifying the development of multi-turn applications.
LangGraph comes with a simple in-memory checkpointer, which we use below. See its documentation for more detail, including how to use different persistence backends (e.g., SQLite or Postgres).
For a detailed walkthrough of how to manage message history, head to the How to add message history (memory) guide.
from typing import Sequence
from langchain_core.messages import BaseMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, StateGraph
from langgraph.graph.message import add_messages
from typing_extensions import Annotated, TypedDict
# We define a dict representing the state of the application.
# This state has the same input and output keys as `rag_chain`.
class State(TypedDict):
input: str
chat_history: Annotated[Sequence[BaseMessage], add_messages]
context: str
answer: str
# We then define a simple node that runs the `rag_chain`.
# The `return` values of the node update the graph state, so here we just
# update the chat history with the input message and response.
def call_model(state: State):
response = rag_chain.invoke(state)
return {
"chat_history": [
HumanMessage(state["input"]),
AIMessage(response["answer"]),
],
"context": response["context"],
"answer": response["answer"],
}
# Our graph consists only of one node:
workflow = StateGraph(state_schema=State)
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
# Finally, we compile the graph with a checkpointer object.
# This persists the state, in this case in memory.
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
This application out-of-the-box supports multiple conversation threads. We pass in a configuration dict specifying a unique identifier for a thread to control what thread is run. This enables the application to support interactions with multiple users.
config = {"configurable": {"thread_id": "abc123"}}
result = app.invoke(
{"input": "What is Task Decomposition?"},
config=config,
)
print(result["answer"])
Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and provides insight into the model's reasoning.
result = app.invoke(
{"input": "What is one way of doing it?"},
config=config,
)
print(result["answer"])
One way of doing task decomposition is by using simple prompting, such as asking the model, "What are the subgoals for achieving XYZ?" This method encourages the model to identify and outline the smaller tasks needed to accomplish the larger goal.
The conversation history can be inspected via the state of the application:
chat_history = app.get_state(config).values["chat_history"]
for message in chat_history:
message.pretty_print()
================================[1m Human Message [0m=================================
What is Task Decomposition?
==================================[1m Ai Message [0m==================================
Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and provides insight into the model's reasoning.
================================[1m Human Message [0m=================================
What is one way of doing it?
==================================[1m Ai Message [0m==================================
One way of doing task decomposition is by using simple prompting, such as asking the model, "What are the subgoals for achieving XYZ?" This method encourages the model to identify and outline the smaller tasks needed to accomplish the larger goal.
Tying it together
For convenience, we tie together all of the necessary steps in a single code cell:
from typing import Sequence
import bs4
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, StateGraph
from langgraph.graph.message import add_messages
from typing_extensions import Annotated, TypedDict
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
### Construct retriever ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = InMemoryVectorStore.from_documents(
documents=splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
### Contextualize question ###
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### Answer question ###
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### Statefully manage chat history ###
class State(TypedDict):
input: str
chat_history: Annotated[Sequence[BaseMessage], add_messages]
context: str
answer: str
def call_model(state: State):
response = rag_chain.invoke(state)
return {
"chat_history": [
HumanMessage(state["input"]),
AIMessage(response["answer"]),
],
"context": response["context"],
"answer": response["answer"],
}
workflow = StateGraph(state_schema=State)
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
result = app.invoke(
{"input": "What is Task Decomposition?"},
config=config,
)
print(result["answer"])
Task decomposition is the process of breaking down a complicated task into smaller, more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts enhance this process by guiding models to think step by step and explore multiple reasoning possibilities. This approach helps in simplifying complex tasks and improving the model's performance.
result = app.invoke(
{"input": "What is one way of doing it?"},
config=config,
)
print(result["answer"])
One way of doing task decomposition is by using simple prompting, such as asking the model, "What are the subgoals for achieving XYZ?" This method encourages the model to identify and outline the smaller steps needed to complete the larger task.
Agents
Agents leverage the reasoning capabilities of LLMs to make decisions during execution. Using agents allow you to offload some discretion over the retrieval process. Although their behavior is less predictable than chains, they offer some advantages in this context:
- Agents generate the input to the retriever directly, without necessarily needing us to explicitly build in contextualization, as we did above;
- Agents can execute multiple retrieval steps in service of a query, or refrain from executing a retrieval step altogether (e.g., in response to a generic greeting from a user).
Retrieval tool
Agents can access "tools" and manage their execution. In this case, we will convert our retriever into a LangChain tool to be wielded by the agent:
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"blog_post_retriever",
"Searches and returns excerpts from the Autonomous Agents blog post.",
)
tools = [tool]
Tools are LangChain Runnables, and implement the usual interface:
tool.invoke("task decomposition")
'Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\n(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user\'s request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.\n\nFig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:'
Agent constructor
Now that we have defined the tools and the LLM, we can create the agent. We will be using LangGraph to construct the agent. Currently we are using a high level interface to construct the agent, but the nice thing about LangGraph is that this high-level interface is backed by a low-level, highly controllable API in case you want to modify the agent logic.
from langgraph.prebuilt import create_react_agent
agent_executor = create_react_agent(llm, tools)
We can now try it out. Note that so far it is not stateful (we still need to add in memory)
query = "What is Task Decomposition?"
for event in agent_executor.stream(
{"messages": [HumanMessage(content=query)]},
stream_mode="values",
):
event["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
What is Task Decomposition?
==================================[1m Ai Message [0m==================================
Tool Calls:
blog_post_retriever (call_WKHdiejvg4In982Hr3EympuI)
Call ID: call_WKHdiejvg4In982Hr3EympuI
Args:
query: Task Decomposition
=================================[1m Tool Message [0m=================================
Name: blog_post_retriever
Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
(3) Task execution: Expert models execute on the specific tasks and log results.
Instruction:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
The system comprises of 4 stages:
(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.
Instruction:
==================================[1m Ai Message [0m==================================
Task Decomposition is a process used in complex problem-solving where a larger task is broken down into smaller, more manageable sub-tasks. This approach enhances the ability of models, particularly large language models (LLMs), to handle intricate tasks by allowing them to think step by step.
There are several methods for task decomposition:
1. **Chain of Thought (CoT)**: This technique encourages the model to articulate its reasoning process by thinking through the task in a sequential manner. It transforms a big task into smaller, manageable steps, which also provides insight into the model's thought process.
2. **Tree of Thoughts**: An extension of CoT, this method explores multiple reasoning possibilities at each step. It decomposes the problem into various thought steps and generates multiple thoughts for each step, creating a tree structure. The evaluation of each state can be done using breadth-first search (BFS) or depth-first search (DFS).
3. **Prompting Techniques**: Task decomposition can be achieved through simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" Additionally, task-specific instructions can guide the model, such as asking it to "Write a story outline" for creative tasks.
4. **Human Inputs**: In some cases, human guidance can be used to assist in breaking down tasks.
Overall, task decomposition is a crucial component in planning and executing complex tasks, allowing for better organization and clarity in the problem-solving process.
We can again take advantage of LangGraph's built-in persistence to save stateful updates to memory:
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
agent_executor = create_react_agent(llm, tools, checkpointer=memory)
This is all we need to construct a conversational RAG agent.
Let's observe its behavior. Note that if we input a query that does not require a retrieval step, the agent does not execute one:
config = {"configurable": {"thread_id": "abc123"}}
for event in agent_executor.stream(
{"messages": [HumanMessage(content="Hi! I'm bob")]},
config=config,
stream_mode="values",
):
event["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
Hi! I'm bob
==================================[1m Ai Message [0m==================================
Hello Bob! How can I assist you today?
Further, if we input a query that does require a retrieval step, the agent generates the input to the tool:
query = "What is Task Decomposition?"
for event in agent_executor.stream(
{"messages": [HumanMessage(content=query)]},
config=config,
stream_mode="values",
):
event["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
What is Task Decomposition?
==================================[1m Ai Message [0m==================================
Tool Calls:
blog_post_retriever (call_0rhrUJiHkoOQxwqCpKTkSkiu)
Call ID: call_0rhrUJiHkoOQxwqCpKTkSkiu
Args:
query: Task Decomposition
=================================[1m Tool Message [0m=================================
Name: blog_post_retriever
Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
(3) Task execution: Expert models execute on the specific tasks and log results.
Instruction:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
The system comprises of 4 stages:
(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.
Instruction:
==================================[1m Ai Message [0m==================================
Task Decomposition is a technique used to break down complex tasks into smaller, more manageable steps. This approach is particularly useful in the context of autonomous agents and large language models (LLMs). Here are some key points about Task Decomposition:
1. **Chain of Thought (CoT)**: This is a prompting technique that encourages the model to "think step by step." By doing so, it can utilize more computational resources to decompose difficult tasks into simpler ones, making them easier to handle.
2. **Tree of Thoughts**: An extension of CoT, this method explores multiple reasoning possibilities at each step. It decomposes a problem into various thought steps and generates multiple thoughts for each step, creating a tree structure. This can be evaluated using search methods like breadth-first search (BFS) or depth-first search (DFS).
3. **Methods of Decomposition**: Task decomposition can be achieved through:
- Simple prompting (e.g., asking for steps to achieve a goal).
- Task-specific instructions (e.g., requesting a story outline for writing).
- Human inputs to guide the decomposition process.
4. **Execution**: After decomposition, expert models execute the specific tasks and log the results, allowing for a structured approach to complex problem-solving.
Overall, Task Decomposition enhances the model's ability to tackle intricate tasks by breaking them down into simpler, actionable components.
Above, instead of inserting our query verbatim into the tool, the agent stripped unnecessary words like "what" and "is".
This same principle allows the agent to use the context of the conversation when necessary:
query = "What according to the blog post are common ways of doing it? redo the search"
for event in agent_executor.stream(
{"messages": [HumanMessage(content=query)]},
config=config,
stream_mode="values",
):
event["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
What according to the blog post are common ways of doing it? redo the search
==================================[1m Ai Message [0m==================================
Tool Calls:
blog_post_retriever (call_bZRDF6Xr0QdurM9LItM8cN7a)
Call ID: call_bZRDF6Xr0QdurM9LItM8cN7a
Args:
query: common ways of Task Decomposition
=================================[1m Tool Message [0m=================================
Name: blog_post_retriever
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
(3) Task execution: Expert models execute on the specific tasks and log results.
Instruction:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
==================================[1m Ai Message [0m==================================
According to the blog post, common ways to perform Task Decomposition include:
1. **Simple Prompting**: Using straightforward prompts such as "Steps for XYZ.\n1." or "What are the subgoals for achieving XYZ?" to guide the model in breaking down the task.
2. **Task-Specific Instructions**: Providing specific instructions tailored to the task at hand, such as asking for a "story outline" when writing a novel.
3. **Human Inputs**: Involving human guidance or input to assist in the decomposition process, allowing for a more nuanced understanding of the task requirements.
These methods help in transforming complex tasks into smaller, manageable components, facilitating better planning and execution.
Note that the agent was able to infer that "it" in our query refers to "task decomposition", and generated a reasonable search query as a result-- in this case, "common ways of task decomposition".
Tying it together
For convenience, we tie together all of the necessary steps in a single code cell:
import bs4
from langchain.tools.retriever import create_retriever_tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
memory = MemorySaver()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
### Construct retriever ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = InMemoryVectorStore.from_documents(
documents=splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
### Build retriever tool ###
tool = create_retriever_tool(
retriever,
"blog_post_retriever",
"Searches and returns excerpts from the Autonomous Agents blog post.",
)
tools = [tool]
agent_executor = create_react_agent(llm, tools, checkpointer=memory)
Next steps
We've covered the steps to build a basic conversational Q&A application:
- We used chains to build a predictable application that generates search queries for each user input;
- We used agents to build an application that "decides" when and how to generate search queries.
To explore different types of retrievers and retrieval strategies, visit the retrievers section of the how-to guides.
For a detailed walkthrough of LangChain's conversation memory abstractions, visit the How to add message history (memory) guide.
To learn more about agents, head to the Agents Modules.